Abstract
We present CoDi-2, a versatile and interactive Multi-modal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multi-modal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi- 2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
Model Architecture
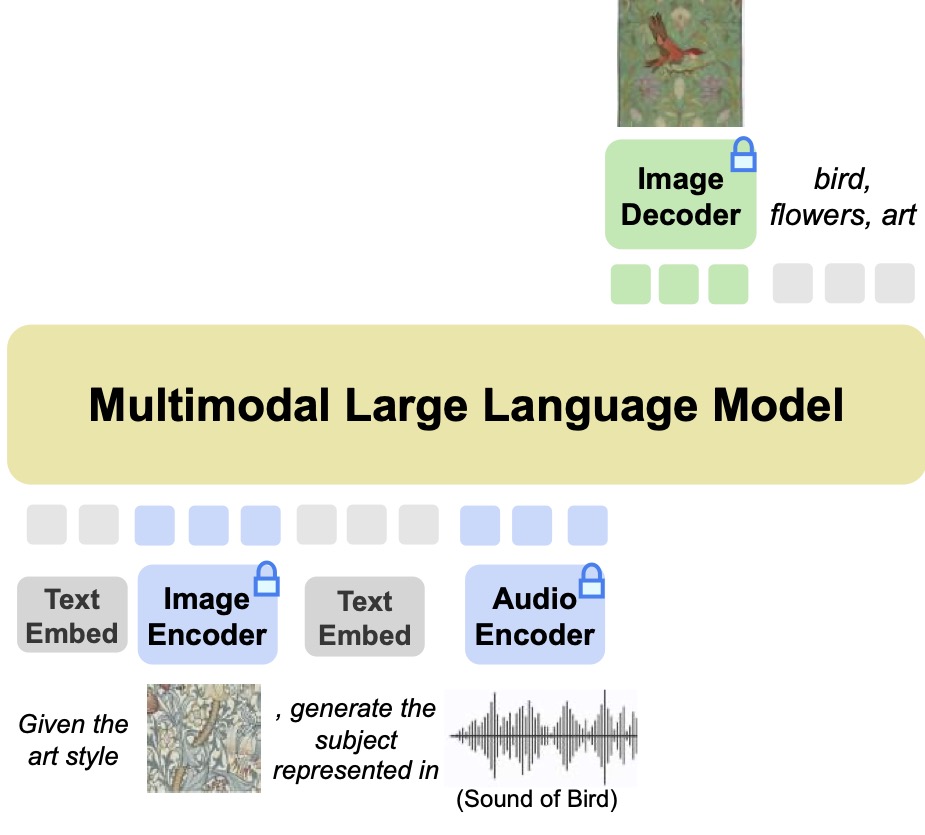
CoDi-2 comprises a multimodal large language model that encompasses encoder and decoder for both audio and vision inputs, as well as a large language model. This architecture facilitates the decoding of image or audio inputs using diffusion models. In the training phase, our approach employs pixel loss obtained from the diffusion models alongside token loss, adhering to the standard causal generation loss.
Tasks
Our model shows strong abilities in the following example tasks type which presents a unique approach to prompting models to generate or transform in-context multimodal content, including instructions, images, audio, video, and combinations thereof.
A. Zero-Shot Prompting.
Zero-shot prompting tasks require the model to reason and generate new content without any prior examples.
B. One-Shot/Few-Shot Prompting.
One-shot or few-shot prompting provides the model with one or a few examples to learn from before performing a similar task. This method is evident in tasks where the model adapts a learned concept from one image to another or creates a new piece of artwork by understanding the styles depicted in provided exemplars.
1. Exemplar learning is a subset of few-shot prompting where the model is explicitly shown an example of the desired output before being asked to apply this learning to a new instance.
2. Concept learning involves the model learning from thes shared concept/attributes of given examples, such as artistic styles or patterns, and then creating new content that exhibits similar concept/attributes.
3. Subject-driven learning focus on generating new content based on a set of provided images.
Multimodal Generation Demos
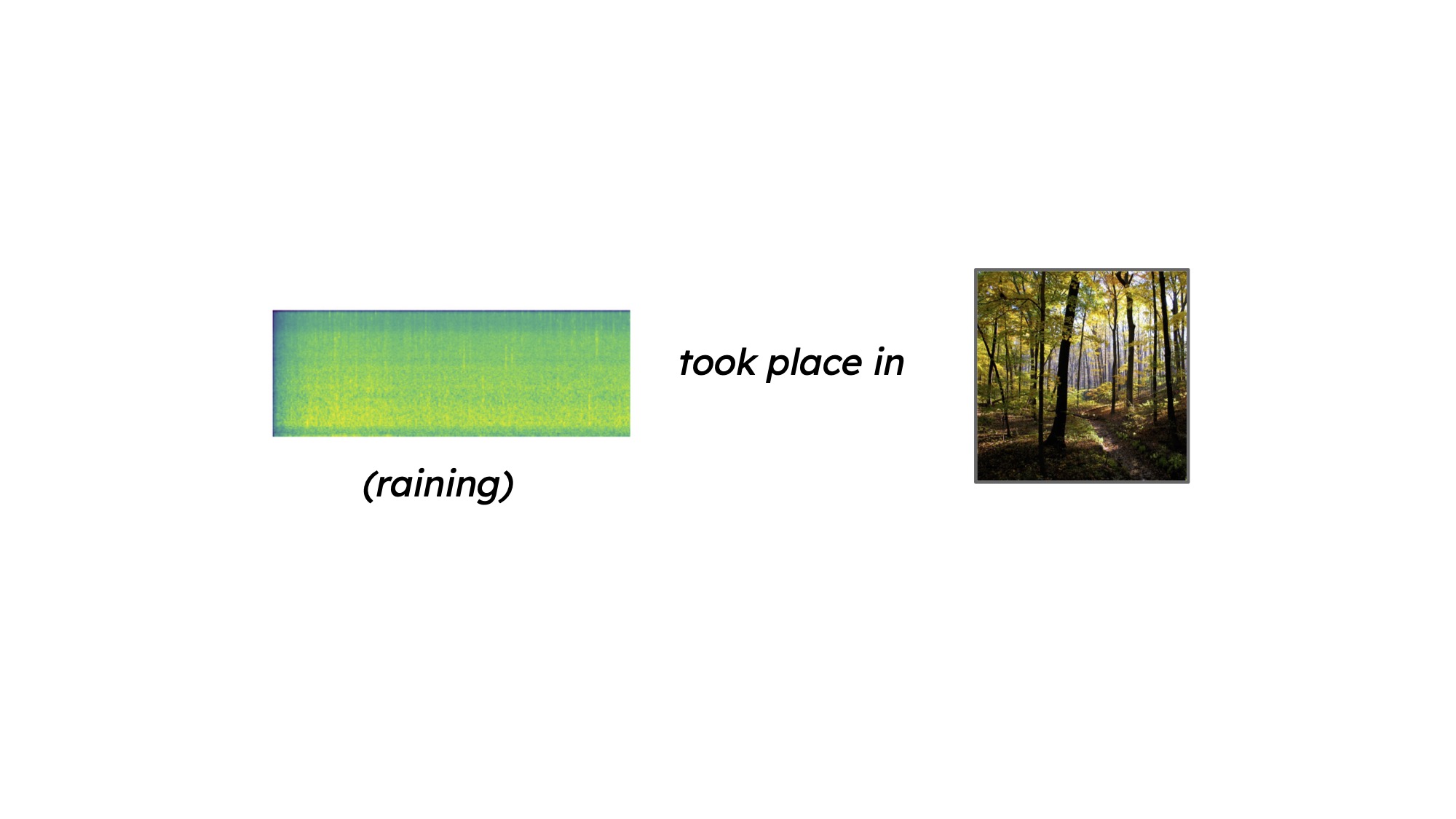





Image Generation Demos











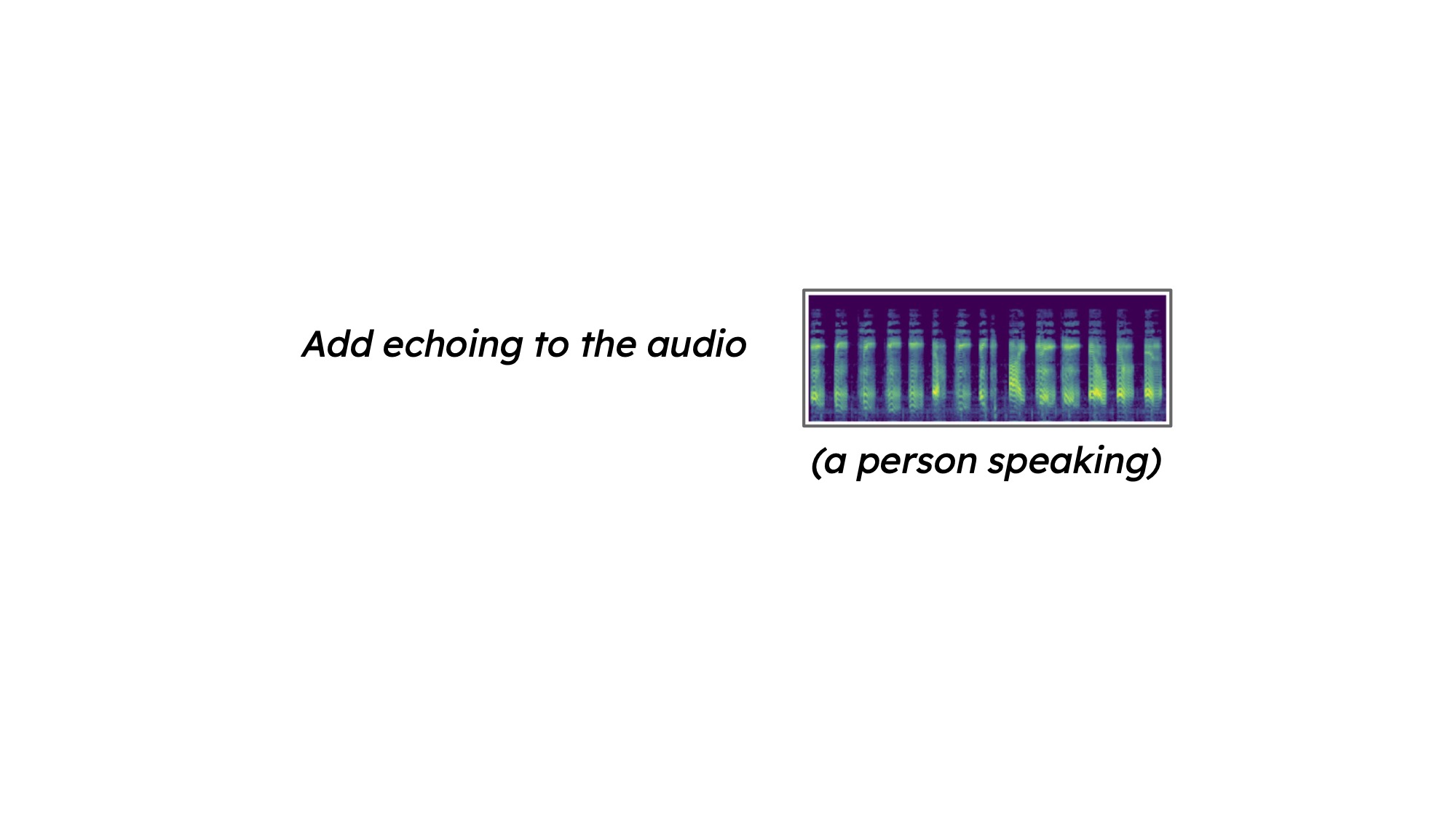
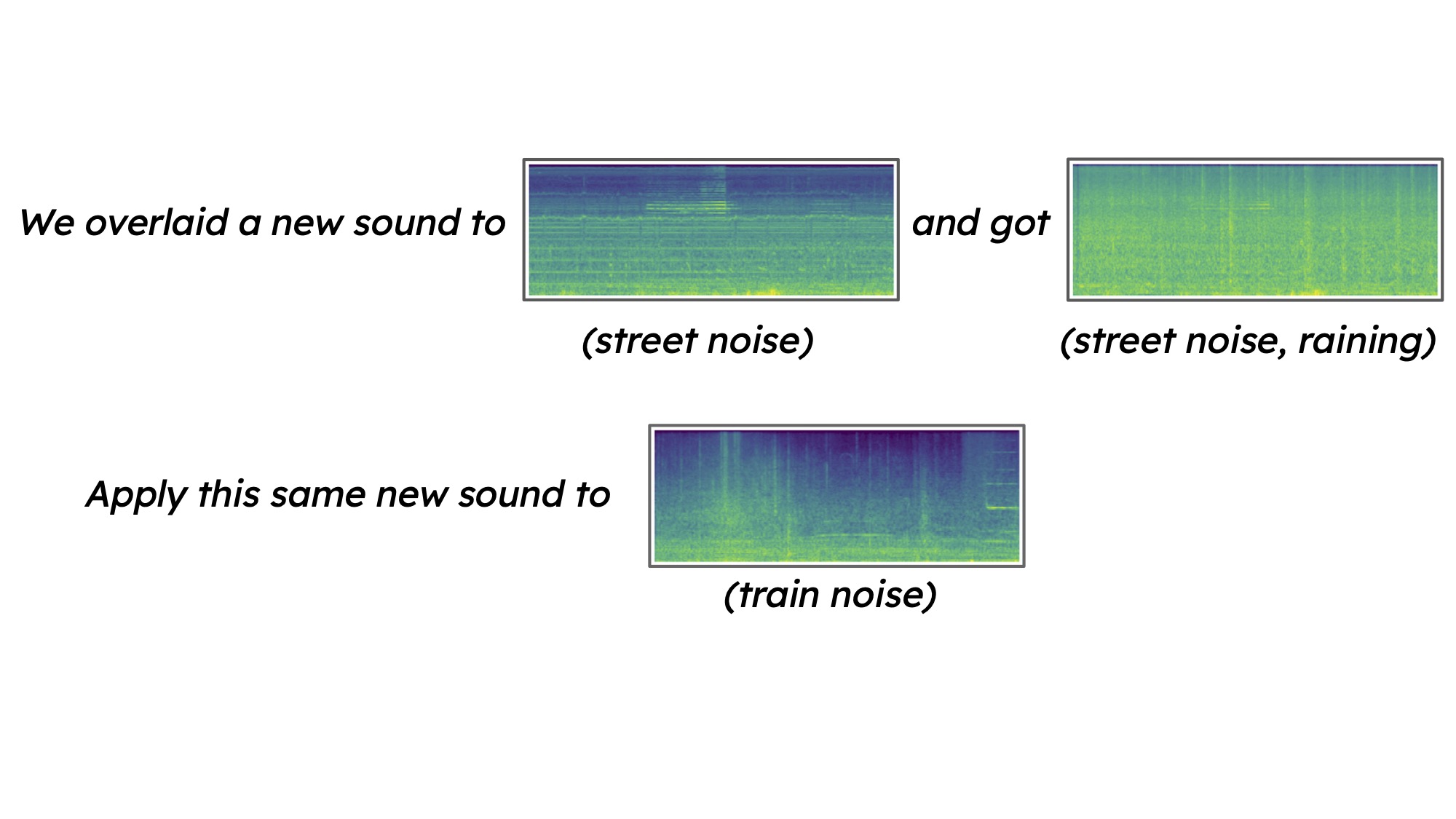
Audio Generation Demos